-
云应用平台(SAE)2015年更新回顾

在过去的2015年里,我们的云应用平台上线了非常多的产品和服务,感谢我们平台上的广大开发者们在这一年里给我们提出的各种反馈和建议,帮助我们把产品和服务做得更好更稳定。
下面就让我们简要的回顾一下这一年里我们主要都推出了哪些新的产品和服务。
独享MySQL是新浪云提供的关系型数据库(RDS)服务,您仅需数十秒钟即可获得一个完整的MySQL服务,并且包括主从、高可用、自动备份、恢复、监控等各种功能。独享MySQL服务会为您启动独立的MySQL实例,分配给您独立使用,您可以根据需要创建多个用户以及多个数据库。相对于共享MySQL服务来说,没有其各种限制并且性能更高。
- 基于Docker容器技术构建,支持部署各种语言的应用,目前支持NodeJS、Go、Java、Python。
- 现在你可以使用最流行的代码版本管理工具来部署你的应用代码了。
- Git代码部署去除了SVN部署中版本目录的概念,让您更自然的组织代码接口、更加方便的开发测试您的应用。
新的PHP-5.6运行环境
- 最新的PHP5版本,让你可以使用各种最新的PHP特性。
- 升级Jetty至9、OpenJDK至7。
- 去除了版本,修改上下文为
/,对各种Java框架提供了更好的支持。
Python运行环境升级
- 升级了Python版本至2.7.9。
CC防火墙
- 进一步提升了HTTP服务的稳定性,帮助云平台上的应用抵抗CC攻击。
- 新增了Header特征过滤功能。
- 接入应用防火墙至云应用全平台,现在Java、Python以及容器云平台的应用都可以直接使用应用防火墙功能了。
- 通过实时日志接口您可以实时获取云应用平台上应用的各种日志,甚至在云端直接对日志进行处理后再返回,更加方便的监控您在云端的应用。
- 通过VPN隧道服务直接拨入新浪云的网络环境,在自己的数据中心或者电脑上直接访问云端提供的各种服务。目前支持OpenVPN协议。
- 让使用独立域名访问的应用可以开启https访问,让应用访问更加安全。
- 支持在MySQL的管理页面中直接恢复您的数据库到14天内的任意时间点。
计费
- 提供了
消费统计7天消费详情等各种报表,让您可以更加清楚明了您的应用在云应用平台上的消费情况。
- 优化了应用体检产品,添加了更多安全检查项。
Storage服务优化
最后,在新的一年里,我们也将继续努力为你提供更多更好的服务和产品。
-
容器云新增Web终端功能
本周我们给云容器云添加了通过 Web终端 登录容器的功能,开发者可以在应用的容器管理面板中点击终端按钮直接登录容器的终端(如下图所示)。
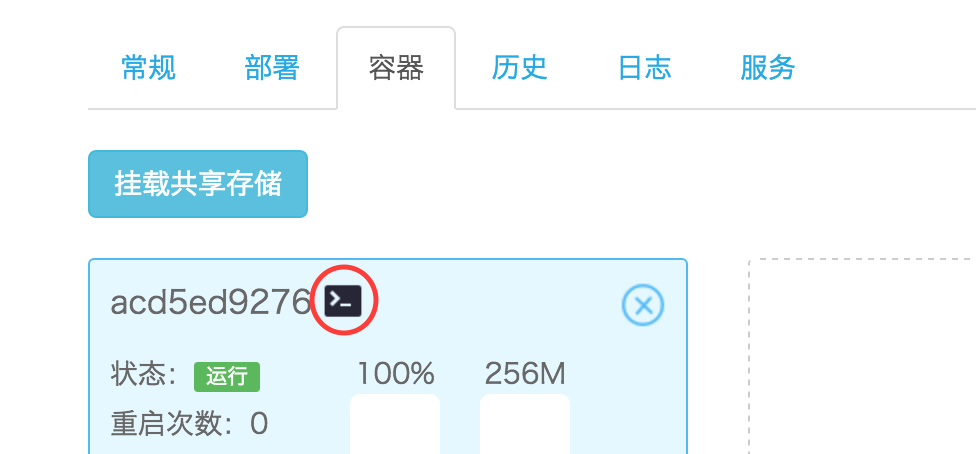
在终端中,开发者可以执行各种熟悉的指令如
top、ps等各种命令来查看当前运行的进程的运行情况,也可以直接在终端里执行一些和应用相关的管理命令,如Django的syncdb等功能。快来使用看看吧:)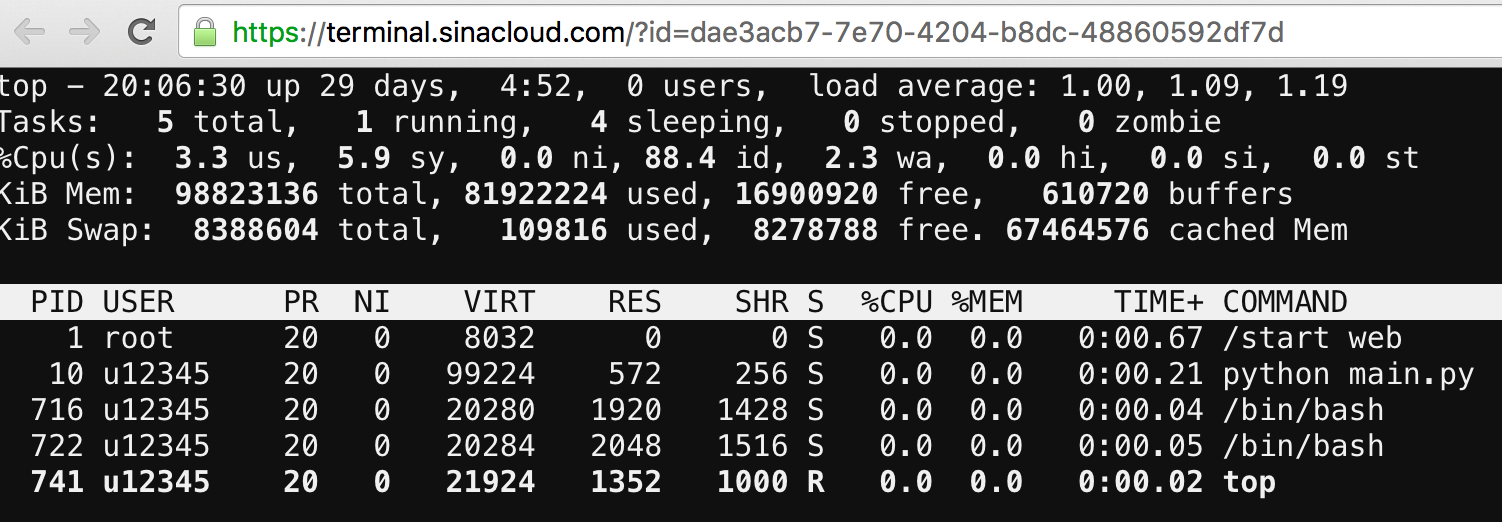
-
一周更新 #52
云容器
- 新增了对Go语言的支持。 文档
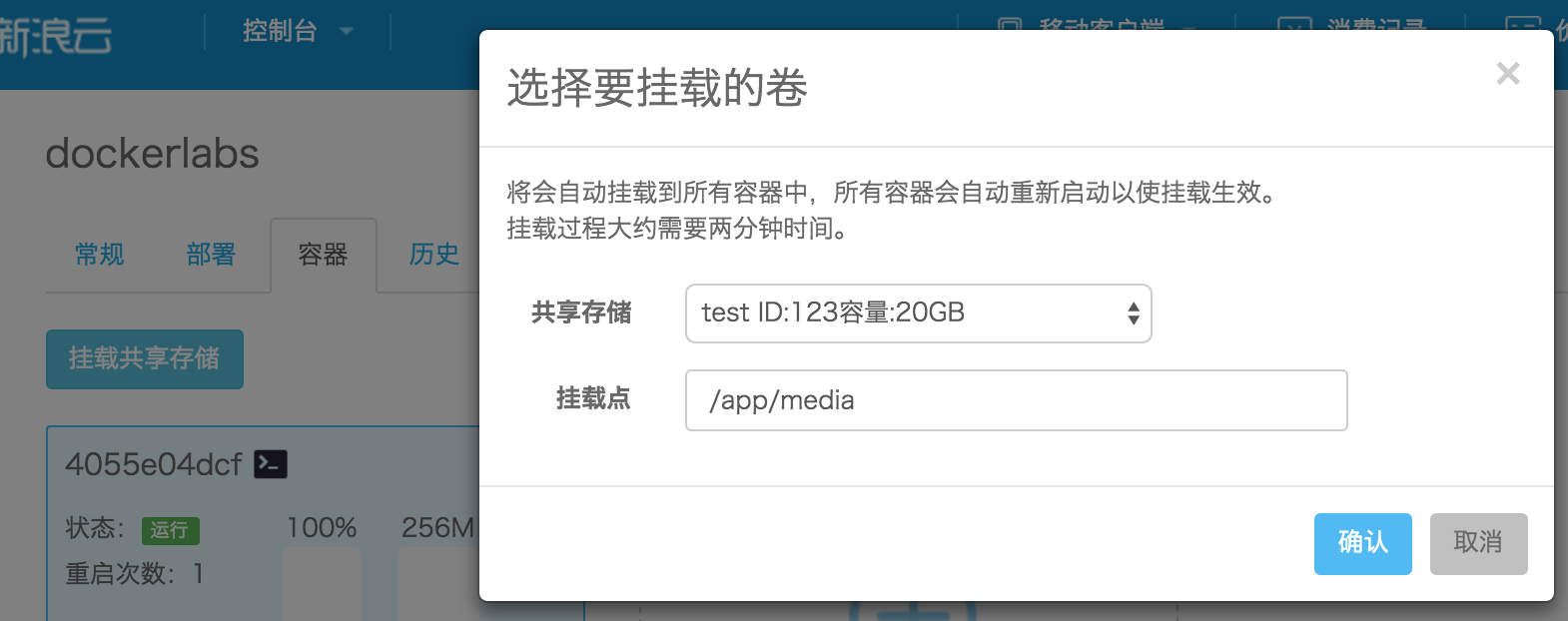
新增共享存储服务。对于不想使用对象存储而希望直接在本地保存数据的开发者,目前可以使用共享存储来存储数据。共享存储可以挂载到容器中的任意路径下,写入该路径下的各种文件会在各个容器之间共享。
云应用
-
应用防火墙(afw)功能升级
近期,我们对应用防火墙的功能做了一些优化:
‘频率拦截’、‘流量拦截’支持全平台
输出了所有规则的拦截统计
在‘业务防火墙页面’的‘拦截日志’展示了所有规则最近几分钟的拦截统计。如:

拦截日志输出到了日志中心
在‘日志中心’添加了防火墙的拦截日志,并且会显示被哪种策略被拦截的。如:因为特征值策略被拦截。

增加了‘特征值过滤’的拦截策略
新加了一种针对http请求的uri和header的过滤规则。通过在防火墙页面设置kv键值对使用。 例如:设置了“uri:*.ini,*.conf”,就会在访问*.ini和*.conf时返回609。
-
记一次SAE Web服务器的调优过程
事情的原因,是发生在某个晚上的9点30左右,SAE的报警系统突然报出了异常,所有的Web服务器的负载突然变得很高,流量也变得异常的大。 这个是很有问题的,在SAE最前面的反向代理上,是部署了SAE自己开发的‘CC防火墙’的,如果出现了异常的被攻击的情况,这些异常的流量是不会到达 Web服务器的,现在这些流量都到达了Web服务器,说明要么是攻击没有被正常判断,要没就是这不是一次攻击。
事实上确实这也不是一次攻击。
随后的分析,我们发现了一堆比较‘奇怪’的应用,为什么说‘奇怪’呢,因为这些应用的访问趋势是这样子的:
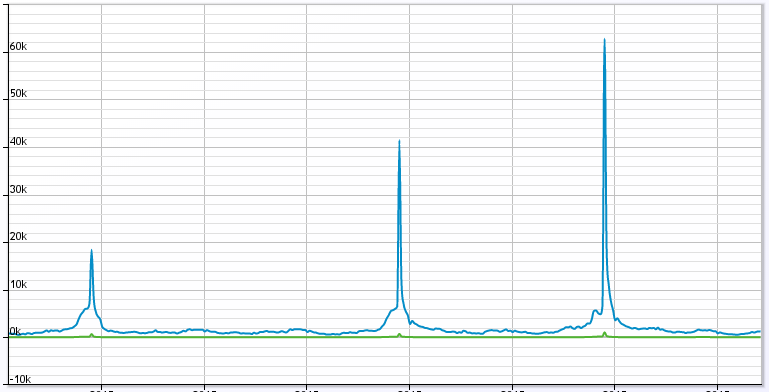
这是其中一个应用的数据,然而在这个应用的帐号下面,大约有十个类似的应用,都是这样的趋势,所以对于我们的Web服务器来说,在特定的时刻要接受 接近10倍左右的流量,对于当前的规模就有点‘顶不住’了。
所以讨论过后,大家的想法还是要对Web服务器进行扩容,来满足这样突发的流量增长。但与此同时,Web服务器也有些不一样的异常,在报警的时候,系统负载 比较高,CPU也没有什么空闲了,但是有个比较特殊的现象,就是system占用的CPU比user占用的CPU要高,这是明显不合理的,一般情况下,system占用CPU较高 意味着系统可能存在瓶颈,比如大量的锁争用等情况。
所以,在着手准备扩容Web服务器的同时,也尝试对现有系统进行一些性能分析,看是否能找到瓶颈,便于做一些优化,提升单Web服务器的容量。
分析的第一步,就是要收集系统运行时的信息,因此我们使用了
perf这个工具,在系统中对httpd进程进行了抓取,并使用 FlameGraph生成相应的火焰图。$ perf record -g -a # 等待收集一段时间后Ctrl-c 退出 $ perf script | stackcollapse-perf.pl | flamegraph.pl > flame.svg最终生成的火焰图如下:
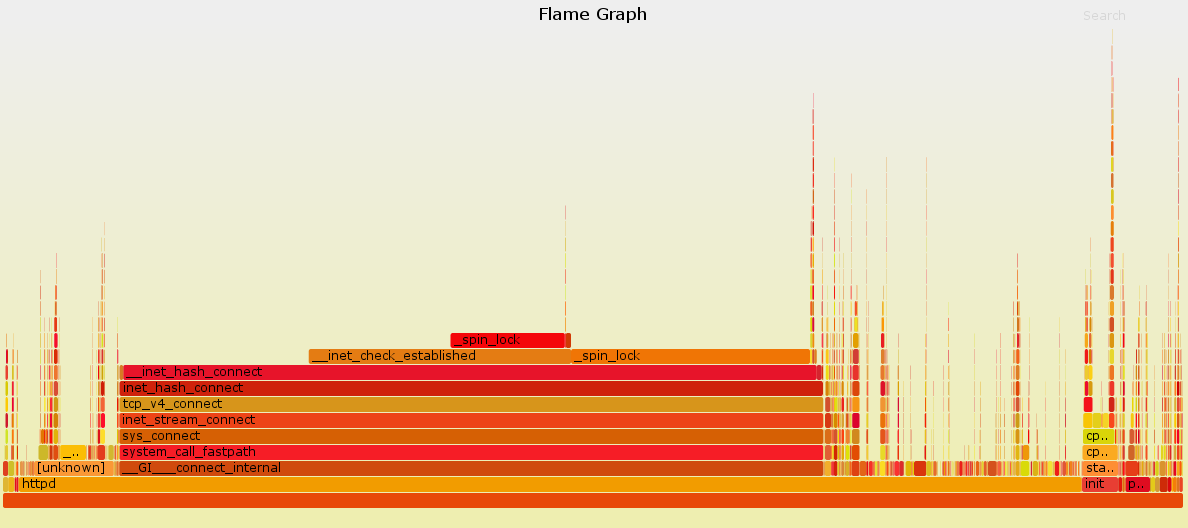
看到这个图,一切都明白了,系统在此阶段调用了太多的connect,尝试建立TCP连接,造成了大量的系统开销,从而影响了整体的性能。 那么为什么会导致这个问题?
用户的代码逻辑非常简单,只是从memcache中取出一个值,然后做一个简单的转换,然后输出。那么,问题就出在了memcache上。
这其实是一个历史遗留问题,SAE的Web服务器是一个纯共享的环境,用户与用户之间,可以做到请求与请求之间的隔离,因此,服务器上的 每个httpd进程都可以为所有的应用服务,实现动态调度,这样的设计,保证了资源的高利用性,能够实现资源利用的最大化。
在当初实现资源隔离的时候,对于memcache,用户初始化memcache时总会帮他建立一个独立的连接,当使用完成,再把连接断掉。 问题就出在了这里,当应用访问量很大,每个请求占用的时间又很短,就出现了频繁和memcache建立连接-断开,又建立连接-断开的死循环。 造成的系统开销非常巨大。
找到了原因,那对应的解决办法就简单了,只需要修改memcache的扩展,把短链接修改为长连接就好,除此之外,如果遇到连接断掉的情况,则 尝试重新连接,保证一个用户的使用不会影响到下个用户。 就这样,最突出的问题就基本解决了。
当然,对于用户来说,其实完全不用关心用的是长连接或者是短连接,不需要调整代码,初始化的Memcache自动地就变成了长连接,完全没有感知。
再看一看调整之后的火焰图:
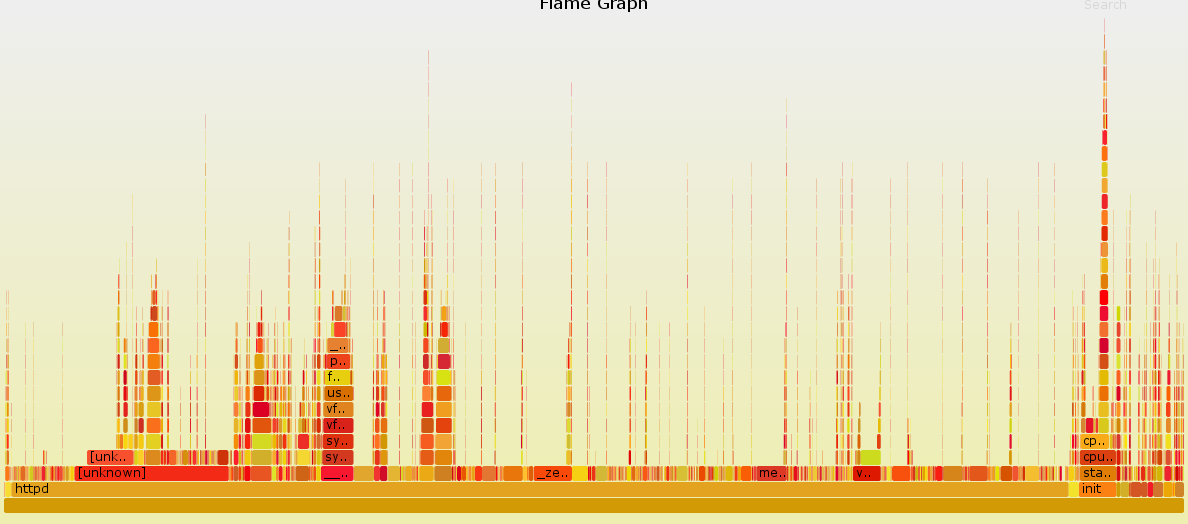
好了不少,没有像之前的火焰图那样非常夸张,相对的消耗都比较平均。
最后在一台即将上线的机器上使用ab测试了一下。
修改前:
Concurrency Level: 100 Time taken for tests: 77.282 seconds Complete requests: 100000 Failed requests: 3863 (Connect: 0, Receive: 0, Length: 3863, Exceptions: 0) Write errors: 0 Non-2xx responses: 3863 Total transferred: 29684301 bytes HTML transferred: 9357111 bytes Requests per second: 1293.96 [#/sec] (mean) Time per request: 77.282 [ms] (mean) Time per request: 0.773 [ms] (mean, across all concurrent requests) Transfer rate: 375.10 [Kbytes/sec] received修改后:
Concurrency Level: 100 Time taken for tests: 16.554 seconds Complete requests: 100000 Failed requests: 6080 (Connect: 0, Receive: 0, Length: 6080, Exceptions: 0) Write errors: 0 Non-2xx responses: 6086 Total transferred: 29450237 bytes HTML transferred: 9218982 bytes Requests per second: 6040.76 [#/sec] (mean) Time per request: 16.554 [ms] (mean) Time per request: 0.166 [ms] (mean, across all concurrent requests) Transfer rate: 1737.32 [Kbytes/sec] receivedQPS 从1293.96 [#/sec] 提升到了6040.76 [#/sec],效果还是比较明显的。
修改了memcache的逻辑,又加上扩容了几台服务器,之后,就没有再出现报警的情况,问题算是得到比较好的解决。
当然,使用了长连接之后,服务器维护的连接数会有很大的提升,基本上从原来了200个连接上升到接近2000个连接,不过对于我们的服务器来说, 这些连接其实不算什么,所以其实也不会有太大的影响,和长连接带来的性能提升相比,还是相当值得的。
subscribe via RSS